云從科技斬獲ICCV2023細(xì)粒度行為檢測(cè)挑戰(zhàn)賽冠軍 打造多模態(tài)技術(shù)閉環(huán)
近日,ICCV2023 細(xì)粒度行為檢測(cè)挑戰(zhàn)賽(Open Fine Grained Activity Detection Challenge)順利結(jié)束,云從科技在行為分類賽道(以下簡(jiǎn)稱OpenFAD23-ICCV23)中斬獲冠軍。
挑戰(zhàn)賽中,云從從容大模型展示了對(duì)多種模態(tài)信息的優(yōu)秀理解和處理能力,從早稻田大學(xué)、軟銀等國(guó)內(nèi)外多家知名企業(yè)、科研機(jī)構(gòu)中脫穎而出,刷新世界紀(jì)錄,再次展示了云從科技在多模態(tài)大模型領(lǐng)域的技術(shù)實(shí)力。
表1: 云從科技在OpenFAD23-ICCV23數(shù)據(jù)集上的表現(xiàn)
專注領(lǐng)先技術(shù)研發(fā) 推動(dòng)視覺(jué)大模型落地應(yīng)用
3D行為識(shí)別技術(shù)相比2D圖像識(shí)別增加了時(shí)間維度的建模,是以人為中心的感知任務(wù)的重要組成部分,一直是人工智能領(lǐng)域的研究熱點(diǎn)。

大模型具有強(qiáng)大的表征能力,并且在多模態(tài)(如語(yǔ)言、音頻、圖像、視頻、視覺(jué)語(yǔ)言)上得到驗(yàn)證,云從結(jié)合實(shí)際業(yè)務(wù)落地需求研發(fā)了基于時(shí)空建模的3D行為識(shí)別基礎(chǔ)大模型。
該模型基于Vision Transformer結(jié)構(gòu)進(jìn)行設(shè)計(jì),通過(guò)自注意力機(jī)制將空間維度和時(shí)間維度的信息進(jìn)行充分關(guān)聯(lián)。
在預(yù)訓(xùn)練階段,采用掩碼重建的方式進(jìn)行自監(jiān)督學(xué)習(xí),為了讓模型同時(shí)學(xué)到場(chǎng)景語(yǔ)義和時(shí)序動(dòng)作,采用偏場(chǎng)景的多模態(tài)語(yǔ)義特征和偏時(shí)序的動(dòng)作特征同時(shí)做為教練模型(teacher)進(jìn)行多分支特征蒸餾,使得模型同時(shí)具有場(chǎng)景語(yǔ)義和時(shí)序動(dòng)作理解能力。
基于大模型預(yù)訓(xùn)練獲得的基礎(chǔ)時(shí)空特征,能夠廣泛用于視頻檢索、視頻問(wèn)答、3D行為識(shí)別、行為關(guān)鍵幀檢測(cè)等下游任務(wù)中。在下游任務(wù)微調(diào)(fine-tune)階段,通過(guò)幀間信息互補(bǔ)的方式自適應(yīng)去除模型冗余的部分,極大提升了下游任務(wù)的訓(xùn)練和推理速度。
表2:云從科技在3D行為識(shí)別領(lǐng)域權(quán)威數(shù)據(jù)集Something-Something V2上的表現(xiàn)
本次OpenFAD23-ICCV23數(shù)據(jù)集包含491個(gè)日常生活中的人類行為,部分行為之間只有極其微小的差別,需要從視頻中抽取多幀畫(huà)面并采用3D時(shí)空建模算法進(jìn)行分析。
云從科技從容大模型憑借在視覺(jué)領(lǐng)域的深厚積累,在OpenFAD23-ICCV23數(shù)據(jù)集粗粒度(coarse)行為類別上精度達(dá)到93.87%,在細(xì)粒度(fine-grain)行為類別上精度達(dá)到91.96%,識(shí)別精度相比上一屆OpenFAD22的冠軍方案高出4%以上。
準(zhǔn)確率的大幅提升表明大模型在時(shí)空關(guān)系特征建模上的優(yōu)勢(shì),意味著3D行為識(shí)別算法已經(jīng)邁入多模態(tài)大模型時(shí)代,將極大提升該技術(shù)的商業(yè)應(yīng)用價(jià)值。目前,該技術(shù)已在金融、安防等領(lǐng)域得到了廣泛應(yīng)用,例如人員動(dòng)作合規(guī)識(shí)別,打架、跌倒等行為檢測(cè)。
多次刷新紀(jì)錄 構(gòu)建多模態(tài)大模型技術(shù)閉環(huán)
今年以來(lái),云從科技多次在多模態(tài)領(lǐng)域?qū)崿F(xiàn)技術(shù)突破。
6月
云從在CVPR 2023提出視覺(jué)大模型自監(jiān)督學(xué)習(xí)方法,僅需過(guò)往1%的數(shù)據(jù)量或者無(wú)需真實(shí)數(shù)據(jù)便可以達(dá)到相同的效果;
7月
云從行人基礎(chǔ)大模型在PA-100K、RAP V2、PETA、HICO-DET四個(gè)數(shù)據(jù)集成為世界第一,商品基礎(chǔ)大模型在MUGE、Product1M 兩個(gè)規(guī)模最大的開(kāi)源中文多模態(tài)商品檢索數(shù)據(jù)集上刷新世界紀(jì)錄;
8月
云從視覺(jué)-語(yǔ)言跟蹤大一統(tǒng)模型在4個(gè)富有挑戰(zhàn)性的跨模態(tài)數(shù)據(jù)集(TNL2K, LaSOT, LaSOTExt, WebUAV-3M)上刷新了四項(xiàng)世界紀(jì)錄;
這使得從容大模型能夠以更好的交互性能,應(yīng)用于金融、安防、政務(wù)、交通、能源、教育、醫(yī)療、文娛等行業(yè)領(lǐng)域。
那么多模態(tài)到底意味著什么?
當(dāng)你輸入一張照片,并用語(yǔ)音或文字“指揮”AI將其部分摳圖修改,并發(fā)送給朋友時(shí),它能立即理解并完成指令。
多模態(tài)交互降低了AI使用的門(mén)檻,使AI有望成為萬(wàn)千大眾都能使用的生產(chǎn)工具和個(gè)人助理。
如今,多模態(tài)大模型已成為大模型邁向通用人工智能(AGI)目標(biāo)的下一個(gè)前沿焦點(diǎn),云從科技持續(xù)專注多模態(tài)技術(shù)研發(fā)與儲(chǔ)備,推動(dòng)視覺(jué)、語(yǔ)言、音頻等技術(shù)的邊界融合,為更多行業(yè)帶來(lái)創(chuàng)新與變革。
您可能感興趣
-
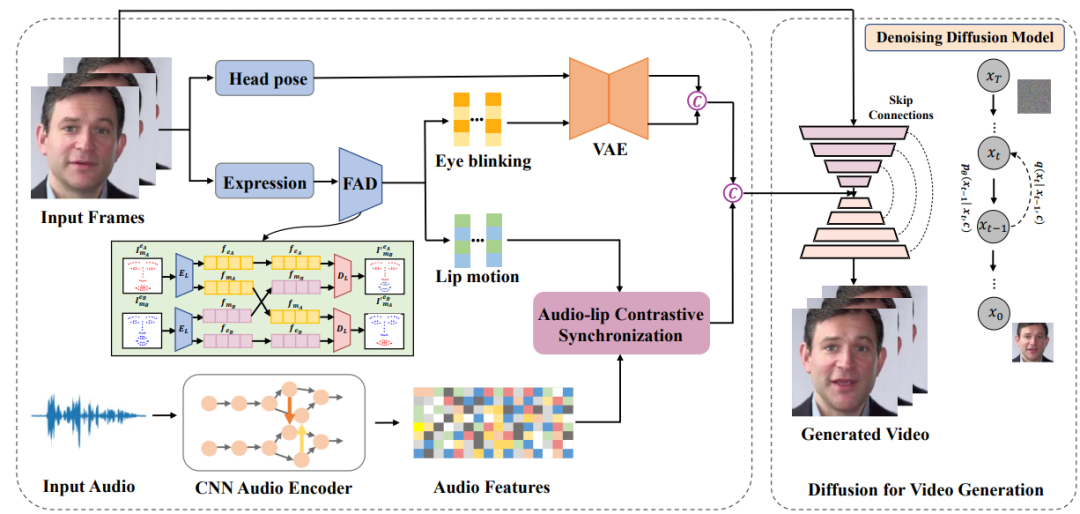 2023-06-27
2023-06-27云從科技與上海交通大學(xué)聯(lián)合研究團(tuán)隊(duì)的《基于擴(kuò)散模型的音頻驅(qū)動(dòng)說(shuō)話人生成》成功入選會(huì)議論文,并于大會(huì)進(jìn)行現(xiàn)場(chǎng)宣講,獲得多方高度關(guān)注。
-
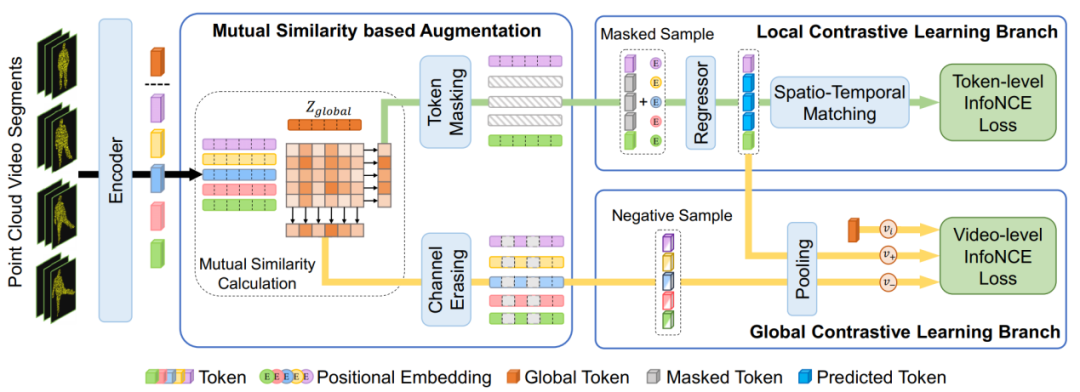 2023-06-27
2023-06-27云從科技及聯(lián)合研究團(tuán)隊(duì)的論文《PointCMP: Contrastive Mask Prediction for Self-supervised Learning on Point Cloud Videos》(基于掩碼預(yù)測(cè)的點(diǎn)云視頻自監(jiān)督學(xué)習(xí))成功入選。
-
 2025-04-01
2025-04-01近日,云從科技與重慶大學(xué)大數(shù)據(jù)與軟件學(xué)院聯(lián)合研發(fā)的編程智能體——CoSEFA(Code SEcurity and Fix Agent)被軟件工程領(lǐng)域頂尖會(huì)議ACM SIGSOFT軟件工程基礎(chǔ)國(guó)際會(huì)議(FSE 2025)正式錄用。







